The history of GPT models by OpenAI is often narrated in broad strokes, with lists of release years, parameter counts, and a few viral headlines about ChatGPT. Yet beneath those surface details lies a deeper, less-documented story of intellectual shifts, engineering gambles, and policy experiments that shaped one of the most influential technologies of the 21st century. Understanding this story requires going beyond the standard timeline to explore why each stage mattered, how researchers worked behind the scenes, and what challenges still remain.
Before the first GPT was introduced in 2018, most natural language processing relied heavily on recurrent neural networks and attention-based hybrids. The Transformer architecture, described in Google’s “Attention Is All You Need” (2017), was still new. GPT, short for Generative Pre-trained Transformer, was built on this architecture and marked a turning point. OpenAI’s gamble was not merely to scale the architecture but to embrace the radical idea that a general-purpose pre-trained model could outperform specialized systems.
This decision, often reduced to a technical footnote in mainstream coverage, was controversial inside the AI community. Many experts doubted that unsupervised training on large internet text could produce useful reasoning skills. The history of GPT models by OpenAI begins, therefore, not as a smooth research program, but as an intellectual bet against prevailing wisdom.
The first GPT, released in 2018 with 117 million parameters, rarely gets attention today. Yet its importance lies in methodology rather than scale. GPT-1 demonstrated that fine-tuning a pre-trained Transformer could match or outperform task-specific models on benchmarks like entailment and question answering.
Few social media posts ever mention the peculiar fact that GPT-1’s training data included BookCorpus, a collection of unpublished novels. That dataset, long overlooked, seeded GPT’s surprising ability for coherent long-form storytelling, an ability later popularized by ChatGPT.
Features: GPT-1 could write simple paragraphs, but it struggled with long, coherent text. It was far from what later became ChatGPT.
When OpenAI released GPT-2 in 2019, the headlines focused on its “dangerous” nature. The lab initially refused to release the full model, fearing misuse for disinformation or spam. What’s less discussed is how this decision became a prototype for OpenAI’s governance experiments. It was one of the first times a research lab openly said: just because we can release something doesn’t mean we should.
The staged release of GPT-2 marked the start of a tradition where the history of GPT models by OpenAI was not only technical but also political. The public reaction, the debates among ethicists, and the eventual full release after monitoring real-world impacts all shaped the cautious strategies that guided later deployments of ChatGPT.
Features: GPT-2 could generate news-like articles and poetry, but it still could not reliably follow detailed instructions.
GPT-3 (2020) is remembered mainly for its size, with 175 billion parameters. Yet the hidden story is the infrastructure leap. Training GPT-3 required a level of distributed compute engineering that few organizations could afford or manage. The lessons learned here formed the backbone of OpenAI’s later ability to deploy products like ChatGPT at massive scale.
Another underappreciated aspect was the emergence of the few-shot learning paradigm. Instead of fine-tuning for every task, GPT-3 could generalize from a handful of examples. This idea, initially seen as a curiosity, became the intellectual foundation for ChatGPT’s later ability to adapt flexibly to millions of user prompts without task-specific retraining.
Features: GPT-3 powered the first apps that could draft emails, write code snippets, or summarize documents, but it often hallucinated facts.
The label “GPT-3.5” may sound like a minor revision, but it introduced one of the most transformative methods in AI history: reinforcement learning from human feedback (RLHF). By systematically ranking model outputs and training GPT-3.5 to prefer human-aligned answers, OpenAI solved the problem of chaotic responses that plagued earlier versions.
When ChatGPT launched publicly in late 2022, it was GPT-3.5’s RLHF fine-tuning that made conversations feel natural, polite, and surprisingly useful. The viral success of ChatGPT cannot be explained by parameter counts or raw scale; it was the subtle integration of feedback systems that made people trust and enjoy it. This period also saw experimental academic tools like Scholar GPT emerge, showing how specialized versions of ChatGPT could be tailored for research-intensive tasks such as literature reviews, data analysis, and academic writing. The history of GPT models by OpenAI therefore pivots here, shifting from a story about research models to a story about global consumer technology.
Features: GPT-3.5 gave birth to ChatGPT in 2022; finally capable of holding long, smooth conversations. But it still couldn’t handle images or very long contexts.
In March 2023, OpenAI released GPT-4. Most coverage focused on its multimodal ability to accept images, but one of the less-discussed features was its robustness across languages. For the first time, a GPT model could perform strongly in dozens of languages without dedicated translation datasets. This hinted at an emergent ability: GPT-4 was not simply a “bigger English model” but a more general reasoning system.
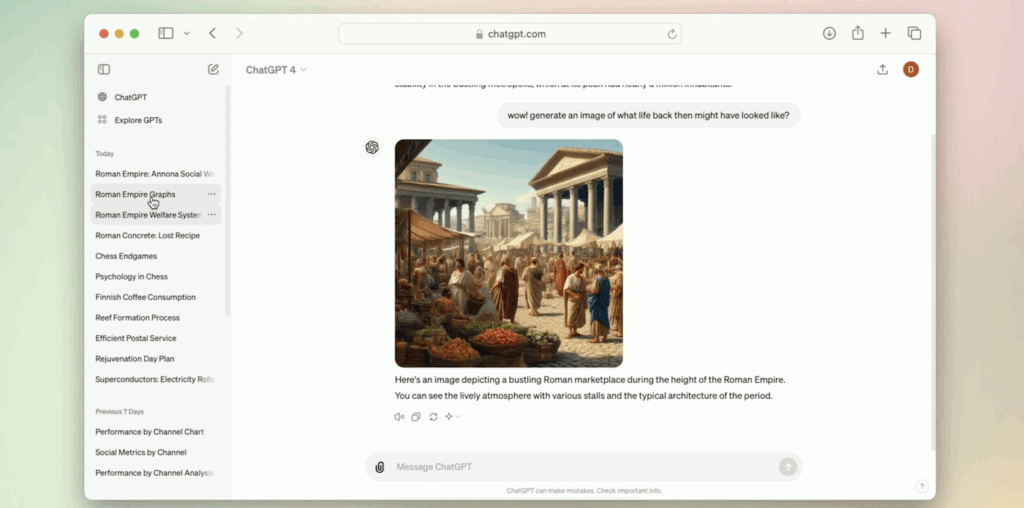
The integration of GPT-4 into ChatGPT marked another milestone in the history of GPT models by OpenAI. Suddenly, everyday users could upload images, ask for interpretations, and receive natural explanations. Yet the public rarely sees the research tradeoffs, such as how much alignment work went into preventing hallucinated image descriptions or how multimodal training reshaped tokenization.
Features: GPT-4 could analyze charts, describe photos, and answer in multiple languages, something unimaginable in the GPT-2 era.
Later in 2023, OpenAI introduced GPT-4 Turbo, an optimized variant powering the default version of ChatGPT Plus. The main story told online was about its lower cost and longer context window (up to 128k tokens). But what deserves attention is how this release redefined accessibility.
By reducing costs, OpenAI made advanced AI more broadly available. The turbo variant democratized experimentation in fields like education, small business automation, and independent research. The history of GPT models by OpenAI thus includes not just breakthroughs in architecture but also breakthroughs in economics of scale, making something so resource-intensive affordable to millions.
Features: GPT-4 Turbo made long-context conversations (128k tokens) possible and much cheaper, allowing students, startups, and small businesses to use advanced AI daily.
In 2024, OpenAI introduced GPT-4o “Omni,” a flagship model that natively understands and responds across text, images, and audio in real time. It delivers GPT-4-level intelligence with lower latency and lower cost, improves non-English performance, and powered a refreshed ChatGPT experience including a desktop app and more natural voice interactions.
Features: Real-time voice conversations with very low delay, native multimodal input and output, strong vision on photos and screen content, faster replies than prior GPT-4 variants, and broader availability in ChatGPT with usage limits for free users.
Now in 2025, GPT-5 represents the culmination of lessons learned across nearly a decade. The improvements go beyond scale: more accurate long-context reasoning, better factual grounding, and deeper multimodal integration. GPT-5 strengthens ChatGPT’s role not just as a chatbot but as a knowledge partner in research, coding, and personal decision-making.
What is rarely noted is how GPT-5 reflects OpenAI’s hybrid identity: part research lab, part product company, part policy experiment. Every iteration carries not only technical refinements but also adjustments in safety, governance, and business models. The history of GPT models by OpenAI is therefore inseparable from its evolution as an institution navigating the balance between innovation and responsibility.
Features: GPT-5 can handle text, images, data tables, and even interactive reasoning, turning ChatGPT into a true research and problem-solving partner.
To see how each generation built on the last, here’s a quick comparison of the features that marked the evolution of GPT models by OpenAI.
| Generation | Year | Key Features | What It Could (or Couldn’t) Do |
|---|---|---|---|
| GPT-1 | 2018 | 117M parameters, early pretrain plus finetune | Wrote short paragraphs, struggled with long coherent structure |
| GPT-2 | 2019 | 1.5B parameters, staged release for safety | Generated news-like articles and poetry, failed at precise multi-step instructions |
| GPT-3 | 2020 | 175B parameters, few-shot learning | Drafted emails, code snippets, and summaries, hallucinations common |
| GPT-3.5 | 2022 | RLHF alignment, public launch of ChatGPT | Held smooth conversations with polite tone, no images, limited long context |
| GPT-4 | 2023 | Multimodal text plus images, stronger multilingual ability | Analyzed charts, described photos, answered in many languages |
| GPT-4 Turbo | 2023 (late) | Optimized GPT-4, cheaper and faster, up to 128k context | Enabled affordable long documents and long conversations for daily use |
| GPT-4o (Omni) | 2024 | Native multimodal across text, image, and audio, real-time low latency, improved non-English, more efficient than prior GPT-4 variants | Held natural voice conversations with interruptions, described photos and screen content live, translated and reasoned across modalities in one model |
| GPT-5 | 2025 | Advanced reasoning, stronger multimodal, better long-context grounding | Handled text, images, and data tables together, supported interactive reasoning as a research partner |
The history of GPT models by OpenAI is more than a sequence of technical upgrades. It is a story of bold bets on unsupervised learning, of governance choices that reshaped AI policy, and of subtle engineering methods like RLHF that made ChatGPT usable for billions. By looking past the headlines, we see how each stage intertwined research, infrastructure, ethics, and economics.
Today, as GPT-5 powers the latest version of ChatGPT, we are reminded that the true significance of this history lies not just in the size of the models, but in the evolving relationship between human society and machine intelligence.